Large Language Models (LLMs) like ChatGPT sure look like magic. And, like magic, it may be super interesting to pull back the curtain and understand how the magic trick works. Stephen Wolfram wrote an introductory article on What Is ChatGPT Doing … and Why Does It Work? in February 2023, just a few months after the release of ChatGPT. The article is also available as a book. Even though there was a lot of evolution in the field of LLMs since then, the article is still a great introduction to the topic.
I love that article, and frequently point beginners to it. And they hate it, because it gets very technical very quickly. Therefore, I’ll try to summarize below the main ideas of that article in a way that is more accessible.
It’s Just Adding One Word at a Time
The main idea behind LLMs is that they generate text one word at a time. The model is trained to predict the next word in a sequence of words, given the previous words. To understand how a model can choose the words, you can think that it uses a list of words and the probabilities that they will come next. For example, for a phrase like “The best thing about AI is its ability to”, the list of probabilities for the next word might look like this:
| Word | Probability |
|---|---|
| learn | 4.5% |
| predict | 3.5% |
| make | 3.2% |
| understand | 3.1% |
| do | 2.9% |
These probabilities come from the corpus of text that the model was trained on. It is natural to think that the model should always choose the word with the highest probability, but if we always do that, we typically get a very boring output. Therefore, we allow the model to choose a word with a lower probability, which makes the output more interesting. The temperature parameter controls how “creative” the model is. The higher the temperature (a real number that goes from 0 to 1), the more likely the model is to choose lower-ranked words.
The model repeats this process for each word in the sequence, generating text one word at a time. For example, if the model generates the word “learn” as the next word, it then uses the phrase “The best thing about AI is its ability to learn” as the context for predicting the next word. This process continues until the model generates the desired amount of text.
Here are three completions I ran in ChatGPT for “The best thing about AI is its ability to”:
- learn, adapt, and solve complex problems, enhancing human potential and transforming industries with innovative solutions.
- analyze vast amounts of data, uncover patterns, and provide insights that would otherwise be impossible for humans to achieve on their own.
- continuously evolve and tackle diverse challenges, enabling more efficient, personalized, and creative solutions across countless domains.
Where the probabilities come from
Although the probabilities do come from the corpus of text that the model was trained on, there’s no giant table with all possible combinations of words and their probabilities.
The reason is that the table would be too big, with a number of entries larger than all the atoms in the universe. Instead of having a table of probabilities, LLMs create a model based on a deep neural network. The model has a fixed size, called the number of parameters. Parameters are numbers that the model learns as it trains. Neural networks work with numbers, so the words are converted to numbers using a technique called embeddings. Embeddings are numerical representations of words done in such a way that similar words have similar embeddings, placing them close to each other. The image below shows embeddings for some words in a 2D space.
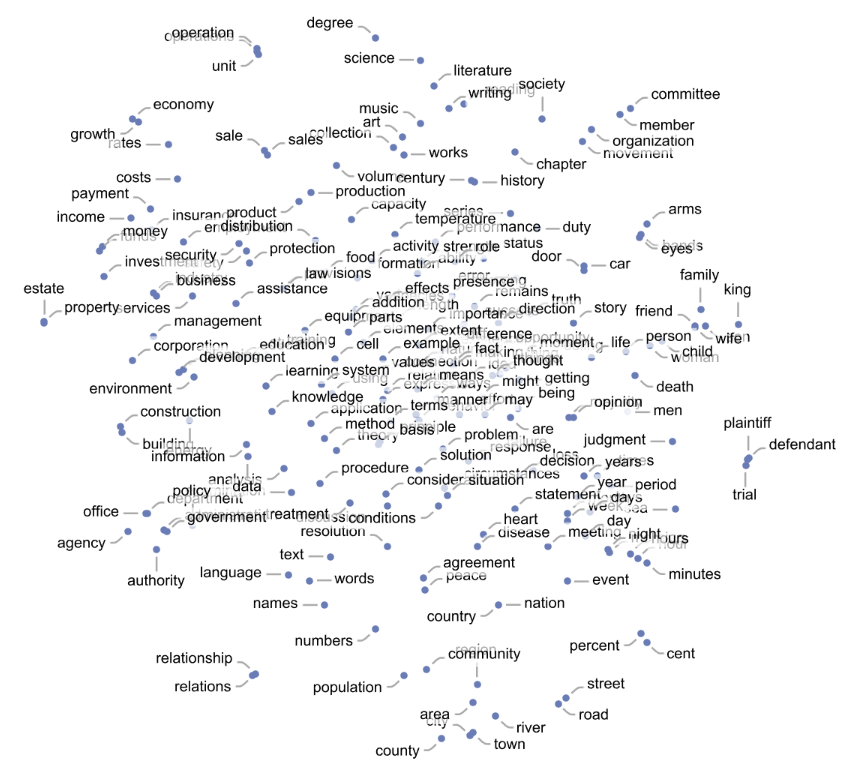
The model shown a sequence of words with a word obscured. It then tries to predict the obscured word’s embedding. The input is converted to numbers, and the numbers are modified (through multiplications and sums) by the parameters of the model. The training program knows the right answer, and if the model gets close to the correct answer, the parameters are reinforced. If the model is far from the correct answer, the parameters are adjusted. This process is repeated trillions of times, with the model getting better and better at predicting the next embedding in a sequence. Once the model is good enough, you can stop training it and start using it to generate text.
It can’t be that simple
At this point, you may be thinking — it can’t be that simple. And you are right. There are a lot of other details that I intentionally skipped to make this post as simple as possible for a beginner. The descriptions above apply to earlier versions of large language models such as GPT-2, back when you could run such a model on your own computer. These earlier models created interesting human-like outputs but they didn’t seem like magic. Today, models are trained on a lot more data, and require a lot more computational power to train. The original GPT-2 had 1.5 billion parameters. The recently released Llama 3.3 has 70 billion parameters.
Another change from these original large language models was the introduction of Reinforcement Learning from Human Feedback (RLHF) training, a way to train a model to generate text that is more likely to be useful to humans. This was done by showing humans the text generated by an LLM and asking them to rate it. The generated text and the ratings are then used to retrain the model to generate better text. This can be done in an external model that interacts with the LLM or you can simply allow the model to update itself. This idea is generally known as fine-tuning and an early version that performed extremely well was implemented in InstructGPT.
Where to go from here
I hope this post helps you understand a little better how LLMs work. If you want to go deeper, I recommend reading the original article by Stephen Wolfram.
Comments